
あの、ListObjectsV2が遅すぎるんですが
この記事はcoins Advent Calendar 2025の5日目の記事です。
GitLFSを作っています
まず私はGitHubのLFSが料金が高すぎて激おこpunpun丸だったので、candylfsというGitLFS互換のSaaSを開発しています。
その際、各パス以下のオブジェクト数と容量を取得するAPI、関数が必要になりました。 最初は愚直に毎回フル取得していたのですが、オブジェクト数が増えると露骨に遅くなる現象を確認しました。
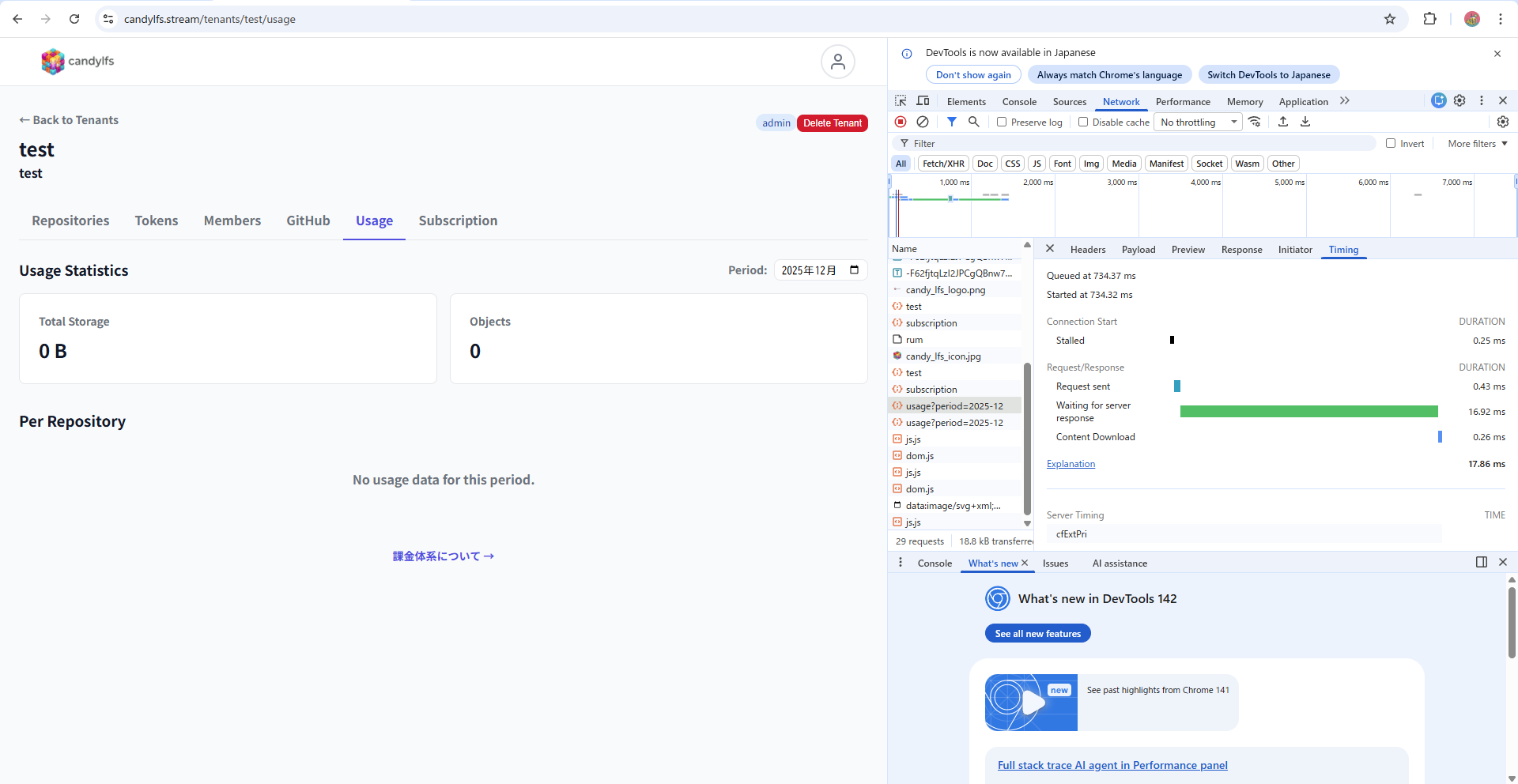
オブジェクト数が1つもない際は、約17msと爆速で帰ってきています。
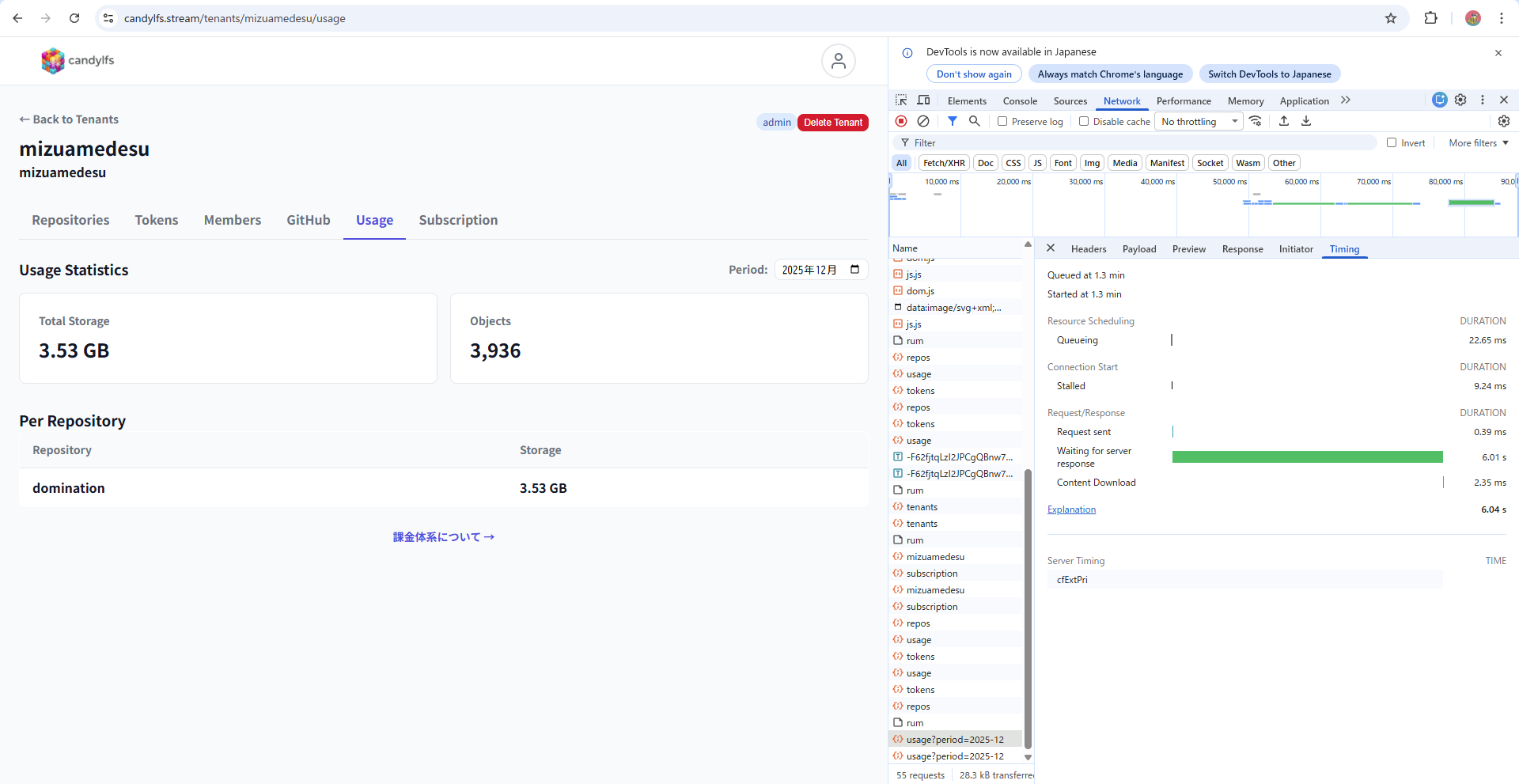
それに対し、オブジェクト数が4000近いリポジトリでは約6秒(6000ms)かかっています。明らかに体感できるレベルで遅いです。
CloudWtachでログ観測
まず恐らくオブジェクト一覧を取得するListObjectsV2 APIがボトルネックになってるだろうなという気持ちがあったのですが、実際にログを仕込んで見てみました。
[getSubscription] START tenantId=tenant-a
[getSubscription] Access check: 11ms
[getSubscription] DynamoDB get: 20ms
[getSubscription] S3 client init: 119ms
[getSubscription] Page 1: 1000 objects, 3121ms
[getSubscription] Page 2: 1000 objects, 2503ms
[getSubscription] Page 3: 1000 objects, 7060ms
[getSubscription] Page 4: 936 objects, 1882ms
[getSubscription] ListObjects total: 4 pages, 3936 objects, 14602ms
[getSubscription] END total: 14753ms
REPORT Duration: 14931.48 ms Memory: 148 MB一部データを伏せていますが、概ねこのようなデータが取れました。 はい、遅いですね。というのもListObjectsV2は一括で全てのオブジェクトリストを取得できるわけではなく、ぺージネーションで1回で取得できるのは最大1000件となっています。そして1回の取得に約2~3秒かかるので、4000個のオブジェクトがある場合は4回のループで合計12秒ほどかかってしまいます。
並列実行
この問題を抱えている人がいないかなと調べた結果、プレフィックスを用いて並列実行をし、高速化している例を発見しました。 https://jboothomas.medium.com/fast-listing-s3-objects-from-buckets-with-millions-billions-of-items-380052fb6faf
LFSはクライアントアップロード時にファイルのハッシュ値を取り、その値をポインターとして持っています。
その為全てオブジェクト名をハッシュ値で保存しているので、プレフィックスが0123456789abcdefのいずれかに均等に分散していることが保証されています。
ですので、最大16並列でListObjectsV2 APIを実行できそうです。
キャッシュ
理論上は最大16倍速になりそうですが、一回の実行コストも16倍になってしまいます。ですので、DynamoDBのキャッシュも同時に実装しました。以下が結果になります。
[getSubscription] START tenantId=tenant-a
[getSubscription] Access check: 12ms
[getSubscription] DynamoDB get: 74ms
[getSubscription] S3 client init: 0ms (cached)
[getSubscription] Parallel scan: 16 requests, 2925ms
[getSubscription] END total: 3012ms, 3936 objects
REPORT Duration: 3032.60 ms Memory: 155 MB[getSubscription] Parallel scan: 16 requests, 2925ms
より大体4倍の高速化が実装できた事がわかります。 最終的に、DynamoDBのキャッシュがある際はそれを使い、ない場合は高速化法で取得した後にキャッシュするという方式になりました。
Lambdaの料金とAPIどっちが高いのか?
オブジェクト数と容量の取得が必要な場面は、マネジメントコンソールのAPIへの表示と、もう一つ実際クライアントがBacth APIを叩いてアップロード要求をしてくる時のクオーターチェックがあります。 マネジメントコンソールの方はキャッシュの問題が発生しリアルタイムでなくとも許されますが、クオーターチェックはある程度厳密ではなくてはなりません。
その為、Batch APIだけは都度真実の値を取得しようと思ったのですが、コストが16倍は流石に許容できません。ですので、瞬間的にはDynamoDBのキャッシュにアトミックカウンターを使い、クライアントへの応答を返した後に、真実の値をListObjectsV2 APIで取得しています。
ここで疑問に思ったのが、16並列化することによるAPI呼び出しコストと、Lambdaの起動時間による課金どっちが高くつくのかです。 Lambdaは256MBで起動しているので、1秒あたり
0.25 GB × 0.0000166667 USD/GB-秒
= 0.000004166675 USD / 秒かかる計算です。 それに対し、ListObjectsV2はクラスA操作に該当し、4.5ドル/100万回呼び出しになります。その為1回16並列実行をする場合、
4.5 ドル / 1,000,000 × 16
= (4.5 × 16) / 1,000,000
= 72 / 1,000,000
= 0.000072 USD / 回となります。その為
N = オブジェクト数、MaxKeys(ページネーション) = 1000、1回あたり2.5秒と仮定
| 項目 | 直列 | 16並列 |
|---|---|---|
| API呼び出し回数 | ⌈N/1000⌉ | 16 × ⌈N/16000⌉ |
| 所要時間 | ⌈N/1000⌉ × 2.5秒 | ⌈N/16000⌉ × 2.5秒 |
N = 17000 の並列実行すると不利な場合を考えてみます
| 項目 | 直列 | 16並列 |
|---|---|---|
| API呼び出し回数 | 17回 | 16 × 2 = 32回 |
| 所要時間 | 42.5秒 | 5秒 |
| Lambda時間コスト | 0.000178 USD | 0.000021 USD |
| APIコスト | 0.0000765 USD | 0.000144 USD |
| 合計 | 0.000255 USD | 0.000165 USD |
損益分岐点を求める
並列化が損になるのは、短縮されるLambda時間コスト < 追加APIコストのときだと分かります。
短縮時間 = 直列時間 - 並列時間
追加API = 並列API回数 - 直列API回数 × 0.0000045
並列が損 = 短縮時間 × 0.0000042 < 追加API × 0.0000045| N | 直列API | 16並列API | 追加API | 短縮時間 | 並列が得か |
|---|---|---|---|---|---|
| 1000 | 1回 | 16回 | +15回 | 0秒 | 損 |
| 5000 | 5回 | 16回 | +11回 | 10秒 | 得 |
| 10000 | 10回 | 16回 | +6回 | 22.5秒 | 得 |
| 16000 | 16回 | 16回 | ±0回 | 37.5秒 | 得 |
| 17000 | 17回 | 32回 | +15回 | 37.5秒 | 得 |
損益分岐点(秒) = 1.07 × (16P - S) / (S - P)
S = ⌈N/1000⌉ (直列API回数)
P = ⌈N/16000⌉ (並列ラウンド数)この計算式に入れると、オブジェクト数が5000辺りで2.95秒になるので、これ以上の場合は並列にした方が安そうです。